The American Trends Panel (ATP), created by the Pew Research Center, is a nationally representative panel of randomly selected U.S. adults living in households. Respondents who self-identify as internet users and who provided an email address participate in the panel via monthly self-administered Web surveys, and those who do not use the internet or decline to provide an email address participate via the mail. The panel is being managed by Abt SRBI.
Members of the American Trends Panel were recruited from two large, national landline and cellphone random-digit-dial (RDD) surveys conducted in English and Spanish. At the end of each survey, respondents were invited to join the panel. The first group of panelists was recruited from the 2014 Political Polarization and Typology Survey, conducted January 23rd to March 16th, 2014. Of the 10,013 adults interviewed, 9,809 were invited to take part in the panel and a total of 5,338 agreed to participate. 1 The second group of panelists was recruited from the 2015 Survey on Government, conducted August 27th to October 4th, 2015. Of the 6,004 adults interviewed, all were invited to join the panel, and 2,976 agreed to participate. 2
Participating panelists provided either a mailing address or an email address to which a welcome packet, a monetary incentive and future survey invitations could be sent. Panelists also receive a small monetary incentive after participating in each wave of the survey.
The analyses in this report depend upon six separate surveys (fielded in December 2015, April, August, December 2016, and March and April 2017). The data for 5,154 panelists who completed any of these six waves were weighted to be nationally representative of U.S. adults.
The ATP data were weighted in a multi-step process that begins with a base weight incorporating the respondents’ original survey selection probability and the fact that in 2014 some panelists were subsampled for invitation to the panel. Next, an adjustment was made for the fact that the propensity to join the panel and remain an active panelist varied across different groups in the sample. The third step in the weighting uses an iterative technique that matches gender, age, education, race, Hispanic origin and region to parameters from the U.S. Census Bureau’s 2014 American Community Survey. Population density is weighted to match the 2010 U.S. Decennial Census. Telephone service is weighted to estimates of telephone coverage for 2016 that were projected from the January-June 2015 National Health Interview Survey. Volunteerism is weighted to match the 2013 Current Population Survey Volunteer Supplement. It also adjusts for party affiliation using an average of the three most recent Pew Research Center general public telephone surveys. Internet access is adjusted using a measure from the 2015 Survey on Government. Frequency of internet use is weighted to an estimate of daily internet use projected to 2016 from the 2013 Current Population Survey Computer and Internet Use Supplement.
Panelists who did not respond to all of the surveys used in this report are missing data for their party identification for waves in which they did not participate. These missing values were imputed using the process described below.
Sampling errors and statistical tests of significance take into account the effects of both weighting and imputation. Interviews are conducted in both English and Spanish, but the Hispanic sample in the American Trends Panel is predominantly native born and English speaking.
The following table shows the error attributable to sampling, weighting and imputation that would be expected at the 95% level of confidence for different groups in the analysis. The margins of error shown reflect the largest margin of error for any of the shifts in support to or from each candidate at each point in time:
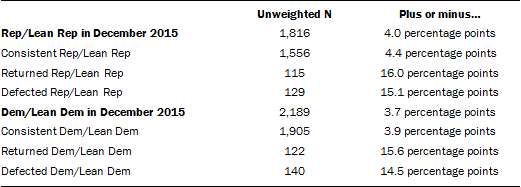
In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
Pew Research Center is a nonprofit, tax-exempt 501(c)(3) organization and a subsidiary of The Pew Charitable Trusts, its primary funder.
About the missing data imputation
The American Trends Panel is composed of individuals who were recruited from two large, representative telephone surveys originally fielded in early 2014 and late 2015. Participants in the panel are sent surveys to complete about monthly. While wave-level response rates are relatively high, not every individual in the panel participates in every survey. The analyses in this report are based on six surveys (fielded in December 2015, April, August, December 2016, and March and April 2017).
Of the more than 5,100 respondents who participated in at least one of the waves in which we collected party affiliation, several hundred respondents (between 9 and 19 percent) did not participate in any given wave. A statistical procedure called multiple imputation by chained equations was used to guard against the analysis being undermined by this wave level nonresponse. In particular, there is some evidence that those who are most likely to participate consistently in the panel are more interested and knowledgeable about politics than those who only periodically respond. Omitting the individuals who did not participate in every wave of the survey might overstate the amount of stability in individuals’ partisanship.
The particular missing data imputation algorithm we used is a method known as multiple imputation by chained equations, or MICE. The MICE algorithm is designed for situations where there are several variables with missing data that need to be imputed at the same time. MICE takes the full survey dataset and iteratively fills in missing data for each question using a statistical model that more closely approximates the overall distribution with each iteration. The process is repeated many times until the distribution of imputed data no longer changes. Although many kinds of statistical models can be used with MICE, this project used a machine learning method called random forests. For more details on the MICE algorithm and the use of random forests for imputation, see the following articles:
Azur, Melissa J., Elizabeth A. Stuart, Constantine Frangakis, and Philip J. Leaf. “Multiple Imputation by Chained Equations: What Is It and How Does It Work?: Multiple Imputation by Chained Equations.” International Journal of Methods in Psychiatric Research 20, no. 1 (March 2011): 40–49. doi:10.1002/mpr.329.
Doove, L.L., S. Van Buuren, and E. Dusseldorp. “Recursive Partitioning for Missing Data Imputation in the Presence of Interaction Effects.” Computational Statistics & Data Analysis 72 (April 2014): 92–104. doi:10.1016/j.csda.2013.10.025.





