Survey Report
Those who study politics have long known that a person’s party affiliation is a strong predictor of how they will vote and what their opinions will be on most political issues. Some of the power of partisanship comes from its relative immutability: Most people remain loyal to a political party.
But over a 15-month period encompassing the 2016 presidential campaign, about 10% of Republicans and Democrats “defected” from their parties to the opposing party.
Those who switched parties were less politically engaged than people who stayed with their parties. And among Republicans and Republican-leaning independents, young people were far more likely than older adults to leave the GOP.
A new study, based on Pew Research Center’s nationally representative American Trends Panel, tracked respondents’ partisan identification over the course of five separate surveys, from December 2015 through March of this year.
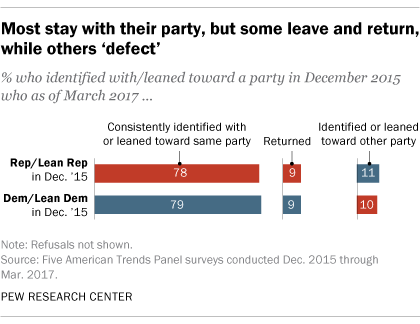
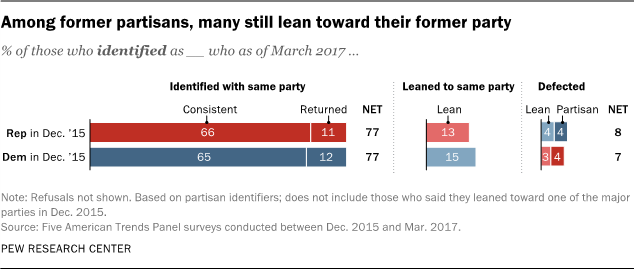
Large majorities stayed with their parties throughout this period. Among those who identified as Republicans or leaned Republican in December 2015, 78% remained with the GOP over four subsequent surveys. Another 9% moved away from the Republican Party at some point, but returned by March 2017.
The numbers are very similar among those who were Democrats in 2015: 79% consistently identified as Democrats or leaned Democratic in all five surveys, while 9% switched parties at some point but came back to the Democratic Party by March.
However, about one-in-ten in both parties changed their partisan leanings. Among those who had identified as Republicans or leaned Republican in the December 2015 survey, 11% either identified as Democrats or leaned Democratic nearly a year and a half later. About the same share of those who had initially aligned with the Democratic Party (10%) identified as Republicans or leaned Republican in March of this year.
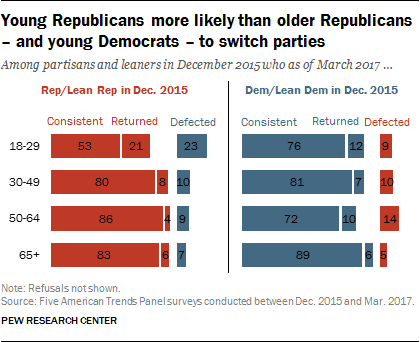
Among Republicans, there were wide age disparities in party-switching, while the differences were more modest among Democrats.
Only about half (53%) of those under 30 who initially identified as Republicans or leaned Republican consistently remained with the party over four subsequent surveys. Among older Republicans, 80% or more consistently identified as Republicans or leaned Republican.
To be sure, 21% of young Republicans left the GOP at some point after December 2015, but returned by March. But nearly a quarter aligned with the Democrats in March: Among those under 30 who initially identified as Republicans or leaned Republican in December 2015, 23% shifted to the Democratic Party (they identified or leaned Democratic).
That is much greater than the share of older Republicans – or Democrats across all age groups – who left their party during this period.
Overall, party-switching is more commonplace among people who are not very engaged by politics than among those who are politically engaged. Just 5% of politically engaged adults – those who are registered to vote and say they “always” vote and also say that they follow what is going on in government and politics “most of the time” – who initially called themselves Republicans leaned Democratic (or identified as Democrats) in the March 2017 survey. Among engaged Democrats, about as many shifted to the GOP (4%).
However, 15% of less engaged adults who initially identified as Republicans or leaned Republican became Democrats, while 12% of less engaged Democrats moved to the GOP.
Party switching and Trump job approval
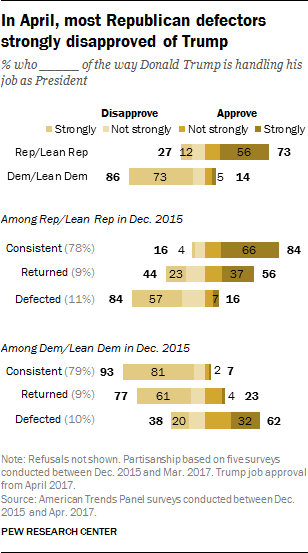
Those who consistently stayed with their parties expressed strong views of Trump, both positive and negative. In April 2017, 84% of those who consistently identified with or leaned toward the Republican Party approved of Trump’s job performance – with 66% approving strongly.
Trump drew lower approval ratings (and fewer strongly approved) among those who left the Republican Party after December 2015 but later returned.
Those who left the Republican Party, by contrast, expressed sharply negative views of Trump: 84% disapproved (57% strongly).
Democrats who stayed with their party – or left and returned – overwhelmingly disapproved of Trump’s job performance. Most who defected from the party gave Trump positive job ratings, but just 32% strongly approved of his job performance.
Party switching among ‘true’ partisans and independents
The analysis above is based on those who identify with a party, as well as those who lean toward a party. The overall patterns are similar when looking just at those who affiliate with the Republican and Democratic parties.
Large majorities of those who initially identified as Republicans and Democrats stayed with their parties from December 2015 through March 2017. In both parties, comparable shares (13% of Republicans, 15% of Democrats) moved from identifying as firm partisans to leaning. Thus some of the stability in leaned partisanship seen above reflects individuals who moved from being partisans to leaners (and vice versa), maintaining a connection to their original party throughout.
Just 8% of those who initially identified as Republicans aligned with the Democrats in March (4% identified as Democrats, 4% leaned Democratic). Similarly, 7% of those who identified as Democrats defected to the GOP (4% identified as Republicans, 3% leaned Republican).
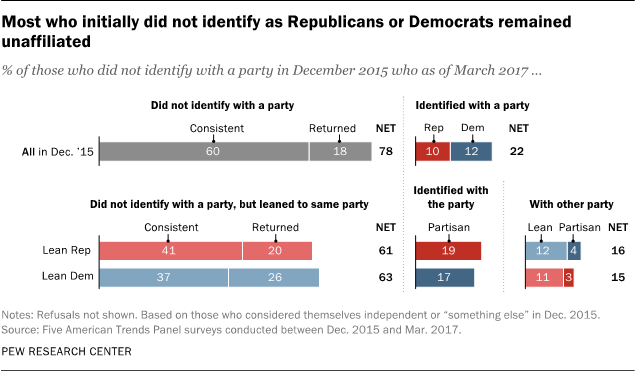
There is somewhat more change among political independents than among partisans. However, 78% of those who did not identify as Republicans or Democrats in December 2015 also did not affiliate with either party in March 2017. Among the remaining 22%, nearly equal shares ended up identifying as Democrats (12%) and Republicans (10%).
Among nonpartisans who leaned toward a party in December 2015, roughly six-in-ten leaned toward the same party in March of this year. There was more movement during this period among leaners than partisans. For instance, 16% of those who initially leaned Republican eventually called themselves Democrats (either identified or leaned Democratic); a comparable share of those who initially leaned Democratic became Republicans or Republican leaners (14%).